开放性研究任务很难处理,因为它们很少遵循可预测的路径。每个发现都可能改变研究方向,使得依赖固定管道变得不可能。这就是多智能体系统变得重要的原因。
By running several agents in parallel, multi-agent systems allow breadth-first exploration, compress large search spaces into manageable insights, and reduce the risk of missing key information.
通过并行运行多个智能体,多智能体系统允许广度优先探索,将大型搜索空间压缩为可管理的洞察,并降低遗漏关键信息的风险。
Anthropic’s engineering team also found that this approach delivers major performance gains. In internal evaluations, a system with Claude Opus 4 as the lead agent and Claude Sonnet 4 as supporting subagents outperformed a single-agent setup by more than 90 percent. The improvement was strongly linked to token usage and the ability to spread reasoning across multiple independent context windows, with subagents enabling the kind of scaling that a single agent cannot achieve.
Anthropic 的工程团队还发现,这种方法带来了显著的性能提升。在内部评估中,以 Claude Opus 4 作为导语智能体、Claude Sonnet 4 作为支持子智能体的系统,比单智能体设置的表现提高了 90%以上。这种改进与令牌使用量以及在多个独立上下文窗口中分散推理的能力密切相关,子智能体实现了单个智能体无法达到的扩展能力。
However, the benefits also come with costs:
然而,这些优势也伴随着成本:
- Multi-agent systems consume approximately fifteen times more tokens than standard chat interactions, making them best suited for tasks where the value of the outcome outweighs the expense.
多智能体系统消耗的令牌约为标准聊天交互的十五倍,因此最适合用于结果价值超过成本的任务。 - They excel at problems that can be divided into parallel strands of research, but are less effective for tightly interdependent tasks such as coding.
它们擅长处理可以分解为并行研究线索的问题,但对于编程等紧密相互依赖的任务效果较差。
Despite these trade-offs, multi-agent systems are proving to be a powerful way to tackle complex, breadth-heavy research challenges. In this article, we will understand the architecture of the multi-agent research system that Anthropic built.
尽管存在这些权衡,多智能体系统正被证明是应对复杂、广度密集型研究挑战的强大方法。在本文中,我们将了解 Anthropic 构建的多智能体研究系统的架构。
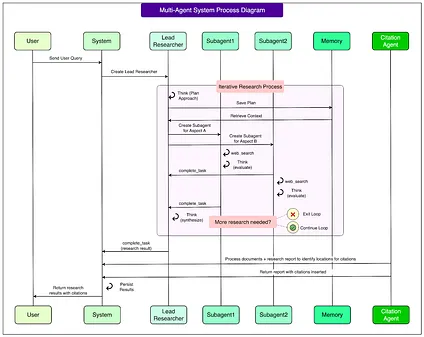
The Architecture of the Research System研究系统的架构
The research system is built on an orchestrator-worker pattern, a common design in computing where one central unit directs the process and supporting units carry out specific tasks.
这个研究系统基于编排器-工作器模式构建,这是计算机领域的一种常见设计,其中一个中央单元指导整个过程,而支持单元执行特定任务。
In this case, the orchestrator is the Lead Researcher agent, while the supporting units are subagents that handle individual parts of the job. Here are the details about the same:
在这种情况下,编排器是主导研究员代理,而支持单元是处理工作各个部分的子代理。以下是相关详细信息:
- Lead Researcher agent: This is the main coordinator. When a user submits a query, the Lead Researcher analyzes it, decides on an overall strategy, and records the plan in memory. Memory management is important here because large research tasks can easily exceed the token limit of the model’s context window. By saving the plan, the system avoids losing track when tokens run out.
主导研究员代理:这是主要的协调器。当用户提交查询时,主导研究员会分析查询,决定总体策略,并将计划记录在内存中。内存管理在这里很重要,因为大型研究任务很容易超出模型上下文窗口的标记限制。通过保存计划,系统可以避免在标记用尽时失去方向。 - Subagents: These are specialized agents created by the Lead Researcher. Each subagent is given a specific task, such as exploring a certain company, checking a particular time period, or looking into a technical detail. Because subagents operate in parallel and maintain their own context, they can search, evaluate results, and refine queries independently without interfering with one another. This separation of tasks reduces duplication and makes the process more efficient.
子代理:这些是由首席研究员创建的专门代理。每个子代理都被分配特定任务,比如探索某家公司、检查特定时间段或调查技术细节。由于子代理并行运行并维护自己的上下文,它们可以独立搜索、评估结果和完善查询,而不会相互干扰。这种任务分离减少了重复工作,使流程更加高效。 - Citation Agent: Once enough information has been gathered, the results are passed to a Citation Agent. Its job is to check every claim against the sources, match citations correctly, and ensure the final output is traceable. This prevents errors such as making statements without evidence or attributing information to the wrong source.
引用代理:收集到足够信息后,结果会传递给引用代理。它的工作是根据来源检查每个声明,正确匹配引用,并确保最终输出可追溯。这防止了诸如无证据发表声明或将信息归因于错误来源等错误。
See the diagram below that shows the high level architecture of these components:
请参见下图,展示了这些组件的高级架构:
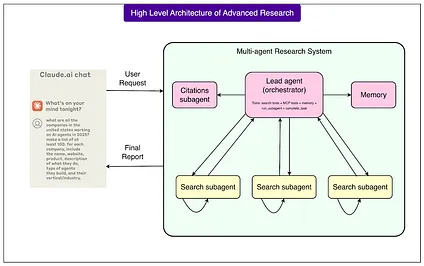
This design differs from traditional Retrieval-Augmented Generation (RAG) systems.
这种设计与传统的检索增强生成(RAG)系统不同。
In standard RAG, the model retrieves a fixed set of documents that look most similar to the query and then generates an answer from them. The limitation is that retrieval happens only once, in a static way.
在标准 RAG 中,模型检索一组与查询最相似的固定文档,然后基于这些文档生成答案。其局限性在于检索只发生一次,是静态的。
The multi-agent system operates dynamically: it performs multiple rounds of searching, adapts based on the findings, and explores deeper leads as needed. In other words, it learns and adjusts during the research process rather than relying on a single snapshot of data.
多智能体系统以动态方式运行:它执行多轮搜索,根据发现的信息进行调整,并根据需要深入探索线索。换句话说,它在研究过程中学习和调整,而不是依赖单一的数据快照。
The complete workflow looks like this:
完整的工作流程如下:
- A user submits a query.
用户提交一个查询。 - The Lead Researcher creates a plan for performing the investigation.
首席研究员制定执行调查的计划。 - Subagents are spawned, each carrying out searches or using tools in parallel.
生成子代理,每个子代理并行执行搜索或使用工具。 - The Lead Researcher gathers their results, synthesizes them, and decides if further work is required. If so, more subagents can be created, or the strategy can be refined.
首席研究员收集他们的结果,综合分析,并决定是否需要进一步工作。如果需要,可以创建更多子代理,或者完善策略。 - Once enough information is collected, everything is handed to the Citation Agent, which ensures the report is properly sourced.
一旦收集到足够的信息,所有内容都会交给引用代理,该代理确保报告得到适当的引用。 - The final research report is then returned to the user.
最终的研究报告随后返回给用户。
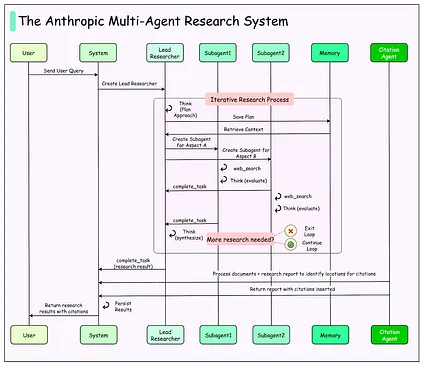
See the diagram below for more details:
详见下图:
This layered system allows for flexibility, depth, and accountability. The Lead Researcher ensures direction and consistency, subagents provide parallel exploration and scalability, and the Citation Agent enforces accuracy by tying results back to sources. Together, they create a system that is both more powerful and more reliable than single-agent or static retrieval approaches.
这个分层系统实现了灵活性、深度和责任制。首席研究员确保方向性和一致性,子代理提供并行探索和可扩展性,引用代理通过将结果与来源联系起来确保准确性。它们共同创建了一个比单一代理或静态检索方法更强大、更可靠的系统。
Prompt Engineering Principles提示词工程原则
Designing good prompts turned out to be the single most important way to guide how the agents behaved.
设计良好的提示词是指导智能体行为的最重要方法。
Since each agent is controlled by its prompt, small changes in phrasing could make the difference between efficient research and wasted effort. Through trial and error, Anthropic identified several principles that made the system work better.
由于每个智能体都由其提示词控制,措辞上的细微变化就可能决定高效研究与徒劳无功之间的差别。通过反复试验,Anthropic 识别出了几个让系统运行更好的原则。
1 - Think like your agents1 - 像你的智能体一样思考
To improve prompts, the engineering team built simulations where agents ran step by step using the same tools and instructions they would in production.
为了改进提示词,工程团队构建了仿真环境,让智能体使用与生产环境中相同的工具和指令逐步运行。
Watching them revealed common mistakes. Some agents kept searching even after finding enough results, others repeated the same queries, and some chose the wrong tools.
观察它们揭示了常见的错误。一些智能体在找到足够结果后仍继续搜索,其他的重复相同的查询,还有一些选择了错误的工具。
By mentally modeling how the agents interpret prompts, engineers could predict these failure modes and adjust the wording to steer agents toward better behavior.
通过在心理上模拟智能体如何解释提示词,工程师们能够预测这些失败模式,并调整措辞来引导智能体产生更好的行为。
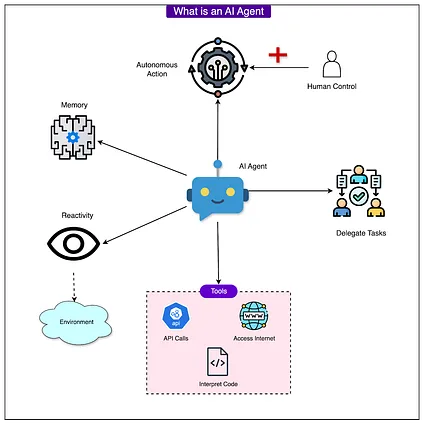
See the diagram below to understand the concept of an agent on a high level:
参见下图以了解智能体的高级概念:
2 - Teach delegation 2 - 教授委托
The Lead Researcher is responsible for breaking down a query into smaller tasks and passing them to subagents.
首席研究员负责将查询分解为较小的任务,并将它们传递给子代理。
For this to work, the instructions must be very clear: each subagent needs a concrete objective, boundaries for the task, the right output format, and guidance on which tools to use. Without this level of detail, subagents either duplicated each other’s work or left gaps. For example, one subagent looked into the 2021 semiconductor shortage while two others repeated nearly identical searches on 2025 supply chains. Proper delegation avoids wasted effort.
为了使这一过程有效运作,指令必须非常明确:每个子代理都需要一个具体的目标、任务边界、正确的输出格式,以及使用哪些工具的指导。如果没有这种详细程度,子代理要么重复彼此的工作,要么留下空白。例如,一个子代理研究了 2021 年半导体短缺,而另外两个则对 2025 年供应链进行了几乎相同的重复搜索。适当的委派可以避免浪费精力。
3 - Scale effort to query complexity3 - 根据查询复杂度调整工作量
Agents often struggle to judge how much effort a task deserves. To prevent over-investment in simple problems, scaling rules were written into prompts. For instance:
代理往往难以判断一项任务应该投入多少精力。为了防止在简单问题上过度投资,在提示中编写了调整规则。例如:
- A simple fact check should involve only one agent making 3–10 tool calls.
简单的事实核查应该只涉及一个代理进行 3-10 次工具调用。 - A direct comparison might need 2–4 subagents, each with 10–15 calls.
直接比较可能需要 2-4 个子代理,每个进行 10-15 次调用。 - A complex research problem could require 10 or more subagents, each with clearly divided responsibilities.
复杂的研究问题可能需要 10 个或更多子代理,每个都有明确分工的职责。
These built-in guidelines helped the Lead Researcher allocate resources more effectively.
这些内置指导原则帮助首席研究员更有效地分配资源。
4 - Tool design matters4 - 工具设计至关重要
The way agents understand tools is as important as how humans interact with software interfaces. A poorly described tool can send an agent down the wrong path entirely.
代理理解工具的方式与人类与软件界面交互的方式同样重要。描述不当的工具可能会让代理完全走向错误的方向。
For example, if a task requires Slack data but the agent only searches the web, the result will fail. With MCP servers that give the model access to external tools, this problem can be compounded since agents encounter unseen tools with varying quality.
例如,如果一个任务需要 Slack 数据,但智能体只搜索网络,结果就会失败。由于 MCP 服务器为模型提供了访问外部工具的能力,这个问题可能会更加严重,因为智能体会遇到质量参差不齐的未见过的工具。
See the diagram below that shows the concept of MCP or Model Context Protocol.
请参见下图,该图展示了 MCP 或模型上下文协议的概念。
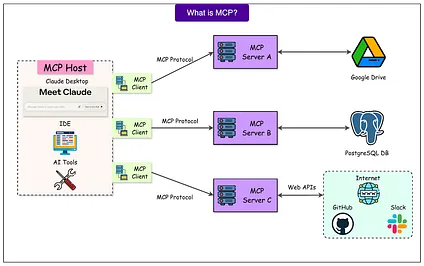
To solve this, the team gave agents heuristics such as:
为了解决这个问题,团队为智能体提供了以下启发式方法:
- Examine all available tools before starting.
在开始之前检查所有可用的工具。 - Match the tool to the user’s intent.
将工具与用户的意图进行匹配。 - Use the web for broad searches, but prefer specialized tools when possible.
使用网络进行广泛搜索,但在可能的情况下优先使用专门工具。
Each tool was carefully described with a distinct purpose so that agents could make the right choice.
每个工具都经过精心描述,具有明确的用途,以便智能体能够做出正确的选择。
5 - Let agents improve themselves5 - 让智能体自我改进
Claude 4 models proved capable of acting as their own prompt engineers. By giving them failing scenarios, they could analyze why things went wrong and suggest improvements.
Claude 4 模型被证明能够充当自己的提示工程师。通过向它们提供失败的场景,它们能够分析出错的原因并提出改进建议。
Anthropic even created a tool-testing agent that repeatedly tried using a flawed tool, then rewrote its description to avoid mistakes. This process cut task completion times by about 40 percent, because later agents could avoid the same pitfalls.
Anthropic 甚至创建了一个工具测试代理,它会反复尝试使用有缺陷的工具,然后重写工具描述以避免错误。这个过程将任务完成时间缩短了约 40%,因为后续的代理能够避免相同的陷阱。
6 - Start wide, then narrow down6 - 先扩大范围,然后缩小范围
Agents often defaulted to very specific search queries, which returned few or irrelevant results.
智能体经常默认使用非常具体的搜索查询,这会返回很少或不相关的结果。
To fix this, prompts encouraged them to begin with broad queries, survey the landscape, and then narrow their focus as they learned more. This mirrors how expert human researchers work.
为了解决这个问题,提示词鼓励它们从广泛的查询开始,调查整体情况,然后随着了解的深入逐渐缩小关注焦点。这反映了专业人类研究者的工作方式。
7 - Guide the thinking process7 - 指导思维过程
Anthropic used extended thinking and interleaved thinking as controllable scratchpads. Extended thinking allows the Lead Researcher to write out their reasoning before acting, such as planning which tools to use or how many subagents to create.
Anthropic 使用扩展思考和交错思考作为可控制的草稿板。扩展思考允许导语研究员在行动前写出他们的推理过程,比如计划使用哪些工具或创建多少个子代理。
Subagents also plan their steps and then, after receiving tool outputs, use interleaved thinking to evaluate results, spot gaps, and refine their next queries. This structured reasoning improved accuracy and efficiency.
子智能体也会规划自己的步骤,然后在接收到工具输出后,使用交错思考来评估结果、发现空白并完善下一次查询。这种结构化推理提高了准确性和效率。
8 - Use parallelization8 - 使用并行化
Early systems ran searches one after another, which was slow.
早期系统逐一运行搜索,速度很慢。
By redesigning prompts to encourage parallelization, the team achieved dramatic speedups. The Lead Researcher now spawns several subagents at once, and each subagent can use multiple tools in parallel.
通过重新设计提示词来鼓励并行化,团队实现了显著的速度提升。主研究员现在可以同时生成多个子代理,每个子代理都能并行使用多种工具。
This reduced research times by as much as 90 percent for complex queries, making it possible to gather broad information in minutes instead of hours.
这将复杂查询的研究时间减少了多达 90%,使得在几分钟内收集广泛信息成为可能,而不是需要几个小时。
Evaluation Methods 评估方法
Evaluating multi-agent systems is difficult because they rarely follow the same steps to reach an answer.
评估多智能体系统很困难,因为它们很少遵循相同的步骤来得出答案。
Anthropic used a mix of approaches to judge outcomes rather than strict processes.
Anthropic 使用多种方法来判断结果,而不是严格的流程。
- Start small: In early development, even tiny changes to prompts had big effects. Testing with just 20 representative queries was enough to see improvements instead of waiting for large test sets.
从小处着手:在早期开发中,即使是对提示的微小更改也会产生很大的影响。仅用 20 个代表性查询进行测试就足以看到改进,而不需要等待大型测试集。 - LLM-as-judge: A separate model graded outputs using a rubric for factual accuracy, citation quality, completeness, source quality, and tool efficiency. Scores ranged from 0.0 to 1.0 with a pass/fail grade. This made the evaluation scalable and consistent with human judgment.
LLM 作为评判者:一个独立的模型使用评分标准对输出进行评分,评估事实准确性、引用质量、完整性、来源质量和工具效率。分数范围从 0.0 到 1.0,并给出通过/不通过的等级。这使得评估具有可扩展性,并与人类判断保持一致。 - Human oversight: People remained essential for spotting edge cases, such as hallucinations or bias toward SEO-heavy sources. Their feedback led to new heuristics for source quality.
人工监督:人类对发现边缘情况仍然至关重要,比如幻觉或对 SEO 密集来源的偏向。他们的反馈促成了新的来源质量启发式方法。 - Emergent behavior: Small prompt changes could shift agent interactions in unpredictable ways. Instead of rigid rules, the best results came from prompt frameworks that guided collaboration, division of labor, and effort allocation.
涌现行为:微小的提示变化可能以不可预测的方式改变智能体交互。与其使用刚性规则,最佳结果来自引导协作、分工和工作量分配的提示框架。
Production Engineering Challenges生产工程挑战
Running multi-agent systems in production introduces reliability issues that go beyond traditional software.
在生产环境中运行多智能体系统引入了超越传统软件的可靠性问题。
- Stateful agents: These agents run for long periods, keeping track of their progress across many tool calls. Small errors can build up, so the system needs durable recovery methods (such as checkpoints, retry logic, and letting agents adapt when tools fail) so that work can resume without starting over.
有状态智能体:这些智能体运行很长时间,跨多个工具调用跟踪其进度。小错误可能会累积,因此系统需要持久的恢复方法(如检查点、重试逻辑,以及让智能体在工具失败时进行适应),以便工作可以恢复而不必重新开始。 - Debugging: Because agents make dynamic, non-deterministic choices, the same prompt may lead to different paths. To diagnose failures, Anthropic added production tracing and monitored high-level decision patterns, while avoiding storage of sensitive user content.
调试:由于智能体会做出动态的、非确定性的选择,同一个提示词可能会导致不同的路径。为了诊断故障,Anthropic 添加了生产追踪功能并监控高级决策模式,同时避免存储敏感的用户内容。 - Deployments: Updates risk breaking agents already mid-task. To avoid this, Anthropic used rainbow deployments, where traffic is shifted gradually from old to new versions, keeping both active during rollout.
部署:更新存在破坏正在执行任务的智能体的风险。为了避免这种情况,Anthropic 使用了彩虹部署,即逐渐将流量从旧版本转移到新版本,在部署过程中保持两个版本同时运行。 - Synchronous bottlenecks: Currently, the LeadResearcher waits for subagents to finish before moving forward. This simplifies coordination but slows down the system. Asynchronous execution could remove these bottlenecks, though it would add complexity in managing state, coordinating results, and handling errors.
同步瓶颈:目前,LeadResearcher 会等待子智能体完成工作后才继续推进。这简化了协调工作,但降低了系统速度。异步执行可以消除这些瓶颈,不过会增加状态管理、结果协调和错误处理的复杂性。
Conclusion 结论
Building multi-agent systems is far more challenging than building single-agent prototypes.
构建多智能体系统比构建单智能体原型要困难得多。
Small bugs or errors can ripple through long-running processes, leading to unpredictable outcomes. Reliable performance requires proper prompt design, durable recovery mechanisms, detailed evaluations, and cautious deployment practices.
小的错误或漏洞可能会在长时间运行的过程中产生连锁反应,导致不可预测的结果。可靠的性能需要适当的提示设计、耐用的恢复机制、详细的评估和谨慎的部署实践。
Despite the complexity, the benefits are significant.
尽管复杂,但收益是显著的。
Multi-agent research systems have shown they can uncover connections, scale reasoning across vast amounts of information, and save users days of work on complex tasks. They are best suited for problems that demand breadth, parallel exploration, and reliable sourcing. With the right engineering discipline, these systems can operate at scale and open new possibilities for how AI assists with open-ended research.
多智能体研究系统已经证明它们能够发现关联性,在大量信息中扩展推理能力,并为用户在复杂任务上节省数天的工作时间。它们最适合那些需要广度、并行探索和可靠来源的问题。通过正确的工程规范,这些系统可以大规模运行,为 AI 如何协助开放式研究开辟新的可能性。
References:参考文献: