在过去的一年里,我大量使用了 AI 编程工具。Claude、Cursor、GitHub Copilot——它们现在都是我日常工作流程的一部分。但我总是遇到同样令人沮丧的情况。
我开始一个新项目时,AI 总是做出错误的默认选择。它会建议使用 SQLite,而我一直用 Postgres。它会以不同于我惯用方式的结构来编写测试。它会忽略我对 Redis 连接池的偏好。每一次,我都不得不停下来说:“不,要按这种方式做。”
来回切换彻底打断了我的思路。
起初,我以为这只是我个人的问题。但后来我开始和其他团队交流,发现这种情况无处不在。工程经理们感到沮丧,因为他们看到团队成员使用的 AI 工具根本不了解公司的架构决策。新来的开发者得到的 AI 生成代码经常违反团队规范。高级开发者则在代码审查中一遍又一遍地修正 AI 建议的同样错误,耗费了大量时间。
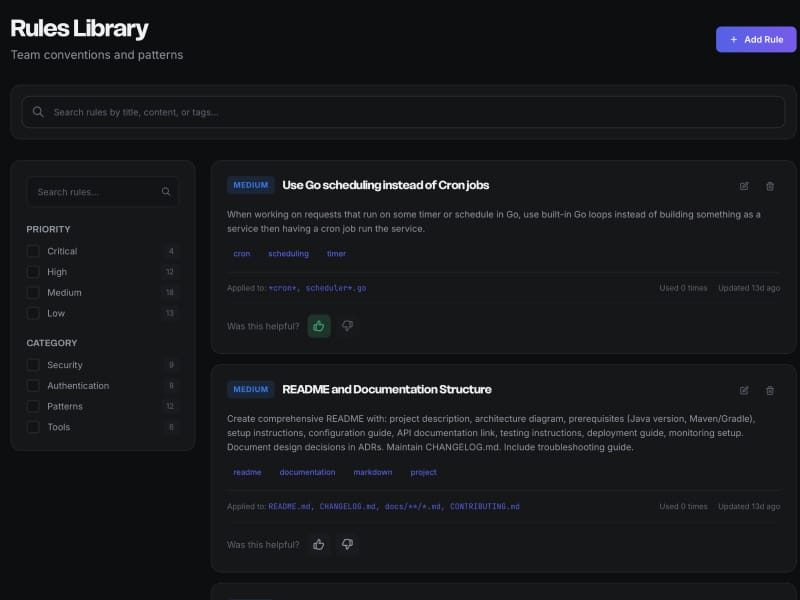
我尝试了常见的解决方案。创建了 .cursorrules 文件。维护了 claude.md 文档。为每个项目设置了详细的上下文文件。但问题在于:这种方式无法在团队中扩展。你有 10 个开发者在用 4 种不同的 AI 工具。标准在不断变化——你更新了密码哈希方式,现在就需要有人去更新每个开发者本地的配置文件。三个月后,每个人对“团队标准”都有了自己的理解。
即使你能让一切保持同步,你还会遇到另一个问题:你不能把所有内容都塞进一个 1000 行的配置文件里。AI 需要在正确的时间获得特定的上下文,而不是一开始就面对一大堆文字。
就在那时,我有了一个想法:如果有一个团队知识的唯一真实来源,能够在 AI 工具需要时,准确地为其提供合适的上下文,会怎么样?
所以我创建了 Cont3xt.dev。
错误的争论
每个人都在纠结哪一个是最适合编程的 LLM。是 Claude?GPT-4?还是 OpenAI 最新的顶级代码 LLM?团队们花费数小时争论到底要统一使用某一个编程 LLM,还是让开发者自行选择。工程负责人则通过对比基准测试,试图找到最适合编程的 AI LLM。
但他们问错了问题。
问题不在于你使用的是哪种模型。问题在于它们都不了解你的上下文。我见过很多团队从一个用于编程的 LLM 模型切换到另一个,希望新模型能了解他们的架构决策。如果模型不知道你一直用的是 Postgres,或者你三个月前弃用了某种认证模式,那么用最好的代码模型也没用。
一款中等水平的编程 LLM,只要有合适的上下文,表现就会超过最先进但没有上下文的模型。每一次都是如此。
上下文缺失的真正代价
我与团队交流得到的数据令人震惊。高级开发者每周花费 10 多个小时反复回答同样的架构问题。“我们为什么选择 Postgres?”“我们如何处理认证?”“我们的 Redis 连接池策略是什么?”这些问题本该由 AI 工具来回答,但它们无法做到,因为没有获取团队的知识。
New developers take weeks to learn team conventions. They make mistakes AI should prevent. They ask questions AI should answer. They write code that doesn’t match team patterns. When I wrote about AI for coding, I focused on individual productivity. But the team angle is where the real pain lives.
新开发者需要数周时间来学习团队的惯例。他们会犯一些本应由 AI 防止的错误。他们会提出一些本应由 AI 解答的问题。他们编写的代码与团队的模式不一致。当我写关于 AI 辅助编程的文章时,我关注的是个人生产力。但真正的痛点在于团队层面。
PR 审核变成了一场噩梦。大约 38%的 PR 因为没有遵循不成文的规则而被拒绝——这些规则 AI 自信地违反了,因为它根本不知道这些规则的存在。安全策略、已弃用的模式、几个月前在 Slack 讨论中做出的架构决策——这些对 AI 来说都是不可见的。
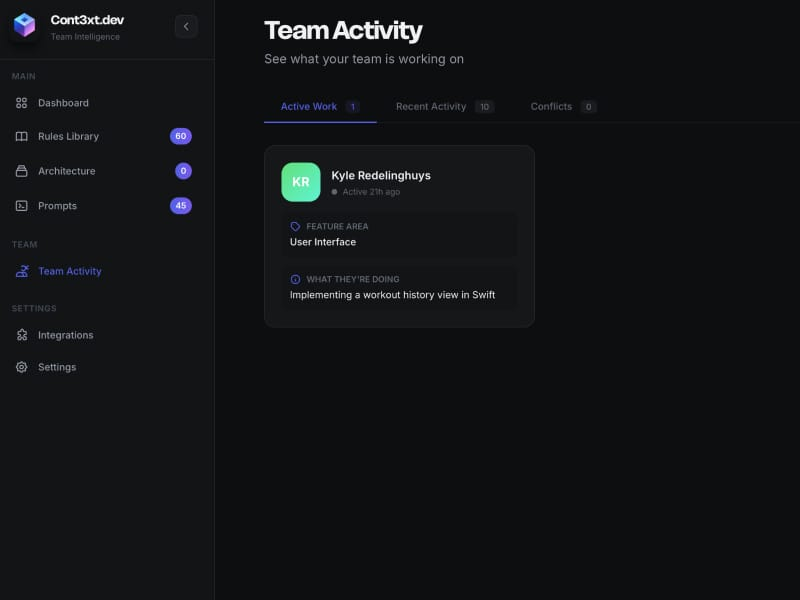
还有一件我没预料到的事:团队成员之间根本不了解彼此在做什么。多个开发者会在不知情的情况下同时修改同一段代码。AI 会提出与正在进行的工作相冲突的建议。合并冲突增加了三倍。
手动解决方案证明了需求的存在。团队为 Cursor、GitHub Copilot、Claude Code 和 VS Code 扩展分别维护着独立的配置文件。有些团队还构建了结构化文件的“记忆库”系统。但要在 50 名开发者、6 种不同 AI 工具之间协调更新?那简直是维护地狱。
我做了什么
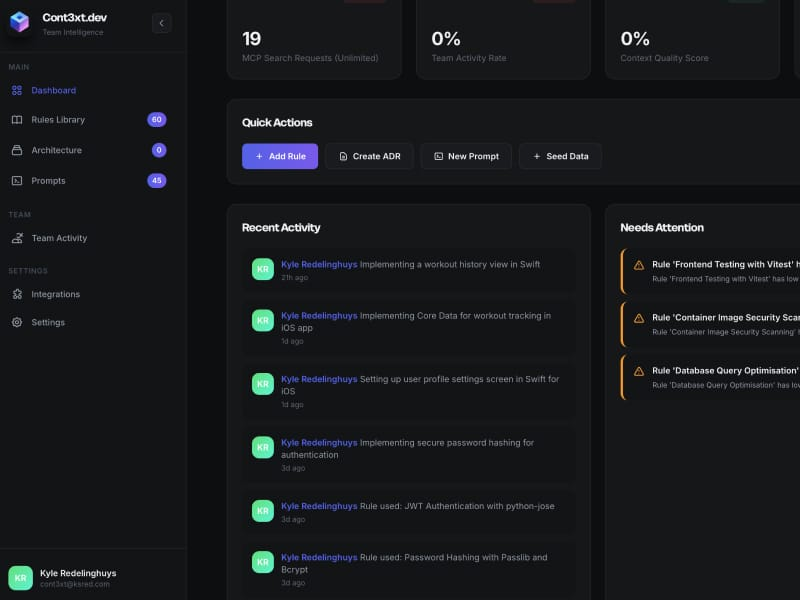
Cont3xt.dev 是一个通用的上下文管理平台。它为团队知识提供单一事实来源,并通过模型上下文协议自动为所有 AI 工具提供相关上下文。
I previously built an MCP server for personal memory, which taught me how powerful the protocol could be. But this needed to work at team scale.
我之前为个人记忆构建过一个 MCP 服务器,这让我认识到该协议的强大之处。但这需要在团队规模下运行。
该平台捕获三种类型的知识:
Context Rules are your coding standards, architectural patterns, security requirements, and team conventions. They’re priority-weighted from 1 (Critical) to 5 (Nice-to-Know). You can attach file patterns, tags, and categories. For example: “Always use bcrypt for password hashing with cost factor 12+” with priority 1 for security-critical code.
上下文规则是你的编码标准、架构模式、安全要求和团队约定。它们按优先级从 1(关键)到 5(了解即可)进行加权。你可以附加文件模式、标签和类别。例如:“始终使用 bcrypt 进行密码哈希,成本因子不低于 12”,对于安全关键代码,优先级为 1。
Architectural Decision Records (ADRs) document why you made specific technical choices. The context, the decision, the consequences, and the current status. These capture the reasoning that prevents teams from revisiting settled decisions. When someone asks “Why Postgres instead of MongoDB?” the AI can point to ADR-001 with the full reasoning.
架构决策记录(ADR)记录了你为何做出特定技术选择。包括上下文、决策、后果和当前状态。这些记录了防止团队反复讨论已定决策的理由。当有人问“为什么用 Postgres 而不是 MongoDB?”时,AI 可以指向 ADR-001 并给出完整的理由。
Prompt Library stores tested, team-approved prompts for common tasks. “Generate Go table-driven tests” or “refactor this function for testability.” These ensure consistent output quality across the team.
提示库存储了经过测试并获得团队认可的常用任务提示,例如“生成 Go 表驱动测试”或“重构此函数以便于测试”。这些提示确保了团队输出质量的一致性。
团队无需维护针对特定工具的配置文件,只需在 Cont3xt.dev 中一次性定义上下文,所有 AI 助手即可在合适的时间获取正确的上下文。
这适用于任何编程大语言模型。无论你的团队偏好 Claude、使用 GitHub Copilot,还是在多个大语言模型之间切换进行编程,他们都能获得相同的上下文。当所有模型都能访问你团队的知识时,关于哪个是最佳编程大语言模型的争论就变得不那么重要了。
技术突破
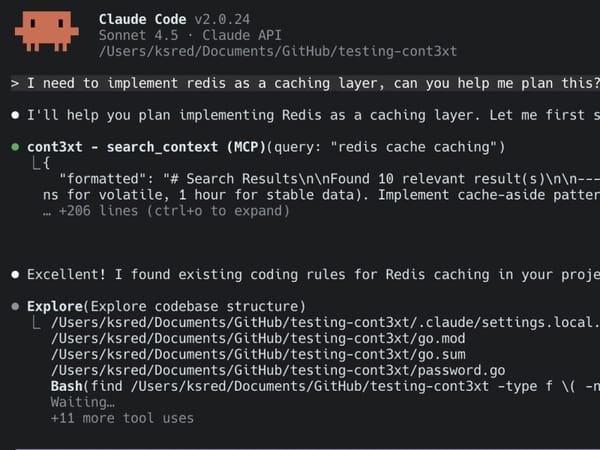
核心创新不仅仅在于存储上下文,而是在不超出 AI 工具的 token 预算的前提下,在正确的时间提供正确的上下文。
我选择了 Postgres 和 pgvector 作为存储层。由于我已经在使用 Postgres,添加向量搜索功能就很自然了,无需另建系统。混合搜索将向量嵌入与 SQL 全文搜索结合,权重分配为 60/40。向量搜索擅长概念匹配(比如“我们如何处理缓存?”会找到 Redis 相关模式),而关键词搜索则能准确捕捉技术术语(比如“bcrypt cost factor”会返回密码哈希规则)。
找到合适的平衡点很难。有时候搜索不会返回你期望的内容,另一些时候又会返回无关的结果。我选择了“返回可能不相关的内容,让 LLM 来筛选”,而不是“不要返回可能相关的内容”。宁可多一点,也不要少了。
最大的突破是本地嵌入。OpenAI 的嵌入 API 虽然不错,但每次搜索查询都要增加延迟,实在太慢了。我实现了一个本地嵌入服务,把响应时间从几百毫秒降到了 10-20 毫秒。令人惊讶的是,这其实很简单——只用了大约一百行代码——如果本地服务宕机,还可以回退到 OpenAI。由于每个搜索查询都需要嵌入,速度非常重要。
I built a production-ready Go package for LLM integration previously, which helped here. The architecture is clean: hybrid search queries across Rules, ADRs, and Prompts in a single operation, returning the top 10 most relevant results regardless of type.
我之前开发了一个可用于生产环境的 Go 包,用于集成 LLM,这在这里起到了帮助作用。架构设计非常简洁:在一次操作中对规则、ADR 和提示进行混合搜索查询,无论类型如何,返回最相关的前 10 个结果。
实际运作方式
用户体验非常流畅。当你的 AI 工具需要上下文时,会自动查询 Cont3xt.dev——你无需操心。我已经在多个项目中使用了几周,它彻底改变了我的工作流程。
我开始一个新项目。AI 立刻知道我使用 Postgres,了解我偏好的文件夹结构,知道我如何编写测试。无需来回沟通。没有“停下来,换种方式做”。我可以在确保标准得到遵守的同时更快推进工作。
团队协作功能是我在意识到开发者经常在不知情的情况下同时修改同一段代码后添加的。你可以实时看到每个人正在做什么。AI 可以在建议更改之前,检查是否已经有人在重构 auth 模块。
真正让我感到惊讶的是,这在回答问题时节省了大量时间。那些高级开发人员经常会遇到的“我们为什么做出这个决定?”的问题,现在由 AI 通过展示相关的 ADR 来处理了。
为什么这对团队很重要
个人生产力的提升固然重要,但团队层面的收益才是真正引人关注的地方。
Onboarding time collapses. New developers have immediate access to all team conventions through their AI tools. They write code that matches team patterns from day one. The ramp-up period drops from weeks to days.
入职时间大大缩短。新开发者通过他们的 AI 工具可以立即获取所有团队惯例。从第一天起,他们编写的代码就符合团队的模式。适应期从几周缩短到几天。
PR reviews become faster. When AI tools follow team standards automatically, fewer PRs get rejected for style or pattern violations. Code reviews focus on logic and design instead of pointing out the same mistakes.
PR 审核变得更快。当 AI 工具自动遵循团队标准时,因风格或模式违规而被拒绝的 PR 更少。代码审核可以专注于逻辑和设计,而不是反复指出相同的错误。
Knowledge preservation happens automatically. With GitHub integration, architectural decisions get extracted from PR discussions and suggested as ADRs. Nothing gets lost in Slack threads anymore.
知识自动得以保留。通过与 GitHub 集成,架构决策会从 PR 讨论中提取出来,并被建议为 ADR。不再有信息遗失在 Slack 线程中。
Standards stay consistent. Update a rule once, every developer’s AI tools immediately use the new standard. No more chasing people down to update their local config files. Whether they’re using different coding LLMs or the same one, everyone gets the same standards.
标准保持一致。只需更新一次规则,每位开发者的 AI 工具都会立即采用新标准。无需再催促大家更新本地配置文件。无论他们使用不同的编码 LLM 还是同一个,所有人都遵循相同的标准。
The metrics from early teams using this have been solid. Context failures dropped significantly. Time spent answering repeated questions fell by hours per week. And new developers started contributing meaningful code much faster.
早期团队使用这一方法的各项指标表现都很出色。上下文失误显著减少。每周在回答重复问题上花费的时间减少了数小时。新开发者也能更快地开始贡献有价值的代码。
现已上线
Cont3xt.dev is live at cont3xt.dev. There’s a free tier for individual developers, and team plans start at 5 seats. The 14-day trial gives you full access to team features with no credit card required.
Cont3xt.dev 已在 cont3xt.dev 正式上线。个人开发者可免费使用,团队套餐从 5 个席位起步。14 天试用期内可完整体验团队功能,无需信用卡。
MCP 集成支持 Cursor、Claude Code、GitHub Copilot、VS Code、JetBrains AI 以及任何兼容 MCP 的工具。只需一次连接,随处可用,无需手动维护配置。
我之所以开发这个工具,是因为我自己有这个需求。手动解决方法效果不佳,团队扩展的问题也很明显。如果你正在使用不了解你团队标准的 AI 工具,或者你在 PR 审核中花费数小时反复纠正同样的错误,这个工具或许能帮到你。
转变
我们正在从手动管理上下文转向智能化的上下文交付。从每个开发者维护自己的配置文件,到团队共享唯一的事实来源。从自信地推荐反模式的 AI 工具,到能够理解你们团队工作方式的 AI 工具。
上下文问题一直是 AI 编程工具的限制因素。团队常常浪费时间争论哪一个是最好的编程大模型,但真正的问题在于它们都没有合适的上下文。有了智能的上下文管理,无论你用的是 Claude、GPT-4,还是最新的顶级代码大模型,只要它们理解你团队的标准,都会变得更加有用。
他们不再是“没有上下文的快速打字员”,而是变成了“了解我们工作方式的团队成员”。
Give it a try. I’d love to hear what you think.