简介
想象一下拥有一个 AI 助手,它不仅能回答你的问题,还能规划你的整个假期、为你的业务谈判交易,或者编写和调试你的代码——这一切都是自主完成的。这不是对遥远未来的憧憬;这就是当今智能体的现实。在突破性基础模型的驱动下,这些智能体正在改变我们与技术互动的方式,推动着 AI 能力的边界。
从本质上讲,智能体不仅仅是软件。它们感知环境,对任务进行推理,并采取行动来实现用户定义的目标。无论是处理复杂查询的客服机器人、收集和分析数据的研究助手,还是在繁忙街道上导航的自动驾驶汽车,智能体正在成为各行各业不可或缺的工具。
智能体 AI 的兴起是一个游戏规则改变者,它能够完成以前被认为过于复杂而无法自动化的任务。但是,强大的能力伴随着巨大的复杂性。挑战不仅在于构建能够有效规划和执行行动的智能体,还在于确保它们能够反思并从其表现中学习。

来源:https://www.simform.com/blog/ai-agent/
什么是 AI 代理?
最简单地说,AI 代理是能够感知环境并采取行动来实现特定目标的系统。Stuart Russell 和 Peter Norvig 在《人工智能:现代方法》中,将代理定义为“任何可以被视为通过传感器感知环境并通过执行器对环境采取行动的东西”。这个定义突出了代理的双重特性——观察、推理、行动。
在现代 AI 背景下,这些智能体由先进的基础模型驱动,可以处理大量数据,使它们能够在最少人工干预的情况下执行复杂任务。它们融合感知和行动的能力,使其成为创建智能自主系统愿景的核心。
日常示例
- ChatGPT 和虚拟助手:生成文本、回答问题、进行对话;通过与设备集成执行设置提醒、控制智能家居等操作
- 自动驾驶汽车:使用摄像头、激光雷达等传感器感知环境,在道路上导航、避开障碍物并做出决策
- 自动化客户服务机器人:处理客户查询、排除故障、推荐产品,提供 7×24 支持
- 研究与编程代理:协助收集信息、分析数据、编写或调试代码
核心特征
AI 智能体由三个关键要素定义:环境、工具、动作。
环境
智能体运行的上下文或空间,例如:
- 数字空间:互联网、数据库(研究代理)
- 物理世界:道路、工厂车间(自动驾驶、机器人)
- 结构化系统:棋盘、文件系统
工具
智能体可访问的工具决定其能力,例如:
- 文本智能体:网络浏览、代码解释器、各类 API
- 编程智能体:导航仓库、搜索文件、编辑代码
- 数据分析智能体:SQL 生成器、知识检索器等
动作
智能体在环境中借助工具可执行的操作,例如:
- 检索与处理信息(如查询数据库)
- 与外部系统交互(如发送邮件、调用 API)
- 修改环境(如编辑文件、导航路线)
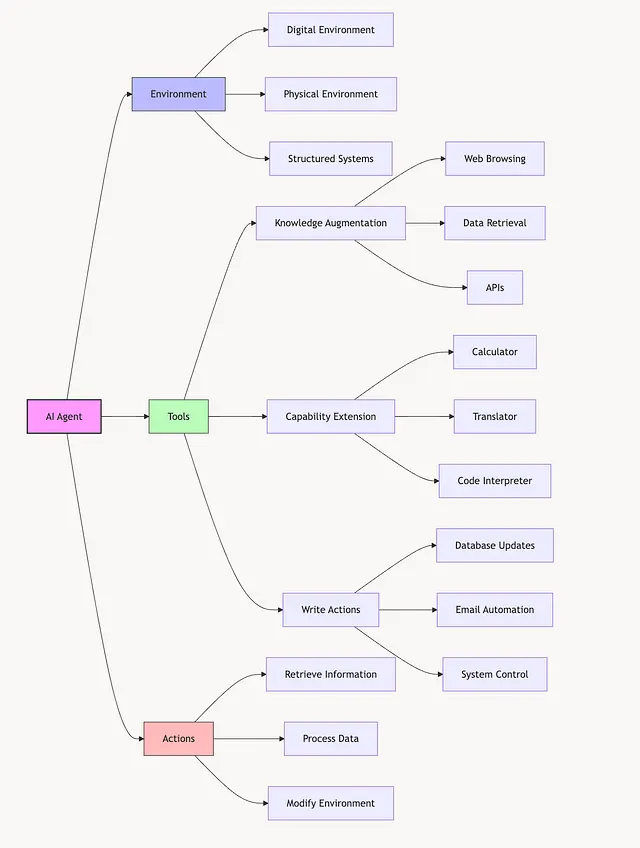
工具:赋能 AI 智能体
工具是 AI 智能体能力的基石,使其能够有效感知并与环境交互。工具可分为三类:知识增强、能力扩展、写入操作。
1)知识增强
帮助智能体收集、检索、处理信息,确保获取最新且相关的数据:
- 网页浏览:获取实时信息,避免过时
- 数据检索:获取文本/图片/结构化数据(如 SQL)
- API:连接外部系统(库存、Slack、邮件等)
2)能力扩展
弥补模型固有限制,使特定任务更准确高效:
- 计算器:提升数学计算精度
- 翻译器:支持多语言沟通
- 代码解释器:编写、执行、调试代码
3)写入操作
让智能体直接修改环境,产生现实影响:
- 数据库更新:更新客户记录等
- 邮件自动化:自动发送/回复/管理邮件
- 系统控制:编辑文件、管理工作流
平衡工具清单
工具越多能力越强,但复杂性也越高,可能导致:
- 决策过载
- 工具使用错误增多
- 工具选择更困难
优化建议:
- 做消融研究评估工具必要性
- 优化工具描述与使用提示
- 监控工具使用模式并精简库存
在 Python 中创建“网络搜索 + 计算器”智能体示例
!pip install -qU langchain langchain_community langchain_experimental duckduckgo-search
from langchain.agents import initialize_agent, AgentType
from langchain.tools import DuckDuckGoSearchRun, Tool
from langchain.llms import OpenAI
from langchain_experimental.tools import PythonREPLTool
import os
def create_search_calculator_agent(openai_api_key):
"""
Creates a LangChain agent with web search and calculator capabilities.
Args:
openai_api_key (str): Your OpenAI API key
Returns:
Agent: Initialized LangChain agent
"""
llm = OpenAI(
temperature=0,
openai_api_key=openai_api_key
)
search = DuckDuckGoSearchRun()
python_repl = PythonREPLTool()
tools = [
Tool(
name="Web Search",
func=search.run,
description="Useful for searching the internet to find information on recent or current events and general topics."
),
Tool(
name="Calculator",
func=python_repl.run,
description="Useful for performing mathematical calculations. Input should be a valid Python mathematical expression."
)
]
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True
)
return agent
if __name__ == "__main__":
OPENAI_API_KEY = " paste your key"
agent = create_search_calculator_agent(OPENAI_API_KEY)
queries = [
"What is the population of Tokyo and calculate it divided by 1000?",
]
for query in queries:
print(f"\nQuery: {query}")
try:
response = agent.run(query)
print(f"Response: {response}")
except Exception as e:
print(f"Error: {str(e)}")
规划:AI 智能体如何把任务做完
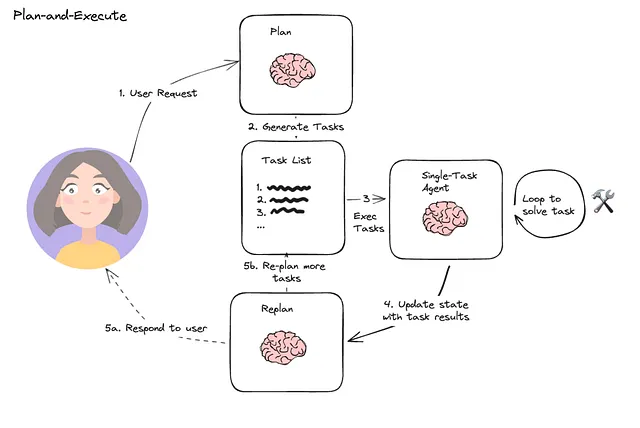
规划让智能体把复杂任务拆解成可执行的行动,并在动态环境中调整路线。
规划的核心组件
- 计划生成:理解目标与约束,形成行动序列(如预算、时间、资源)
- 计划验证:检查可行性与逻辑性(启发式规则、评估器)
- 执行:调用工具并从环境获取反馈
- 反思与纠错:失败时定位原因、更新计划并重试
规划方法
- 分层规划:从高层目标拆到具体子任务
- 逐步规划:一步步决定下一步行动(常与链式思维提示结合)
- 并行规划:同时执行多个步骤以提速
- 动态规划:根据新信息/失败实时调整
规划挑战
- 多步骤误差传播:步骤越多,整体成功率下降(例如单步 95%,10 步约降到 60%)
- 目标不一致:计划偏离用户目标或违反约束
- 工具依赖:工具调用失败会拖垮流程
- 资源效率:多余步骤造成成本/延迟增加
更好规划的策略
- 规划与执行解耦:先计划→再验证→再执行
- 意图分类:先判断用户意图,再生成匹配计划
- 反思驱动迭代:执行前自检“可能出什么问题?”
- 多智能体协作:规划/验证/执行分工
示例(规划思路)
任务:查找并总结去年关于 AI 的顶级研究论文
计划:
- 用网络搜索检索顶级 AI 会议
- 查询这些会议的论文
- 总结前 5 篇论文摘要
- 汇总并返回结果
反思:若论文过时,优化检索条件重试
创建具有规划能力的 Agent(Python 示例)
%%capture --no-stderr
%pip install --quiet -U langgraph langchain-community langchain-openai tavily-python
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
_set_env("TAVILY_API_KEY")
from langchain_community.tools.tavily_search import TavilySearchResults
tools = [TavilySearchResults(max_results=3)]
from langchain import hub
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
prompt = hub.pull("ih/ih-react-agent-executor")
llm = ChatOpenAI(model="gpt-4o-mini")
agent_executor = create_react_agent(llm, tools, state_modifier=prompt)
import operator
from typing import Annotated, List, Tuple
from typing_extensions import TypedDict
class PlanExecute(TypedDict):
input: str
plan: List[str]
past_steps: Annotated[List[Tuple], operator.add]
response: str
from pydantic import BaseModel, Field
class Plan(BaseModel):
steps: List[str] = Field(description="different steps to follow, should be in sorted order")
from langchain_core.prompts import ChatPromptTemplate
planner_prompt = ChatPromptTemplate.from_messages(
[
("system",
"针对目标给出简洁的分步计划;每一步是独立任务;不要加入多余步骤;最后一步产出最终答案;不要跳步。"),
("placeholder", "{messages}"),
]
)
planner = planner_prompt | ChatOpenAI(model="gpt-4o-mini", temperature=0).with_structured_output(Plan)
from typing import Union
class Response(BaseModel):
response: str
class Act(BaseModel):
action: Union[Response, Plan] = Field(
description="要么直接回复用户(Response),要么给出需要继续执行的计划(Plan)"
)
replanner_prompt = ChatPromptTemplate.from_template(
"""针对目标更新分步计划:不加多余步骤;最后一步产出最终答案;只保留仍需执行的步骤。
目标:
{input}
原计划:
{plan}
已完成步骤:
{past_steps}
请更新计划;若无需继续则直接给出回复。"""
)
replanner = replanner_prompt | ChatOpenAI(model="gpt-4o-mini", temperature=0).with_structured_output(Act)
from typing import Literal
from langgraph.graph import END, StateGraph, START
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i+1}. {step}" for i, step in enumerate(plan))
task = plan[0]
task_formatted = f"""计划:
{plan_str}
你需要执行第 1 步:{task}"""
agent_response = await agent_executor.ainvoke({"messages": [("user", task_formatted)]})
return {"past_steps": [(task, agent_response["messages"][-1].content)]}
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
async def replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan": output.action.steps}
def should_end(state: PlanExecute):
if "response" in state and state["response"]:
return END
else:
return "agent"
workflow = StateGraph(PlanExecute)
workflow.add_node("planner", plan_step)
workflow.add_node("agent", execute_step)
workflow.add_node("replan", replan_step)
workflow.add_edge(START, "planner")
workflow.add_edge("planner", "agent")
workflow.add_edge("agent", "replan")
workflow.add_conditional_edges("replan", should_end, ["agent", END])
app = workflow.compile()反思:从错误中学习
反思使智能体能够从失败中恢复、改进策略,并在多步骤任务中持续提升可靠性。反思通常贯穿任务前/中/后:
- 任务前:评估计划可行性、识别风险
- 执行中:监控结果是否偏离计划,及早发现失败
- 任务后:确认任务是否完成,分析失败原因
反思机制
- 自我批评:用提示/规则审视结果是否达标
- 错误分析:定位失败点与根因
- 重新规划:基于错误更新计划并重试
- 外部评估:由另一个模型/智能体做评审
反思的收益
- 提高准确性:减少重复犯错
- 增强韧性:对工具失败/意外更能恢复
- 提升资源效率:早发现早止损
- 持续学习:形成迭代闭环
反思的挑战
- 延迟与成本上升:多一步反思就多 token 与时间
- 多步骤定位困难:错误会级联传播
- 反思质量参差:容易生成泛泛建议
失败模式
1)规划失败
- 使用不可用工具或错误参数
- 目标/约束不满足(如预算不符、目的地错误)
- 误判任务完成(以为做完了但实际没做完)
2)工具故障
- 工具输出错误/不完整(bug、配置问题)
- “翻译层”映射错误(把计划映射到错误 API/端点)
3)效率问题
- 步骤冗余:重复搜索、重复调用
- 高延迟:响应过慢
- 成本超支:用昂贵模型做简单任务
失败评估指标(建议)
- 计划与工具调用的有效率
- 无效/冗余动作频次
- 失败模式的分类与频率
- 单工具贡献的成功率
安全考虑
主要风险
- 恶意行为:越权访问、泄露敏感数据、有害输出、写入操作被滥用、代码注入
- 易受操纵:提示注入、数据投毒、社会工程
- 过度依赖外部工具:API/第三方被攻破带来的攻击面
缓解策略
- 防御性提示:明确约束范围、执行前安全校验、多层检查
- 访问控制:基于角色授权、限制工具清单、沙箱隔离
- 输入输出验证:清理输入、审查输出动作
- 日志与监控:实时监控、审计追踪
- 人在回路:高风险操作必须人工审批、可随时介入回退
- 模型与工具加固:定期更新、对外部工具做安全测试
常用智能体框架

结论
AI 智能体结合推理、规划与行动能力,能够自主解决复杂问题,推动效率与生产力提升。但其开发与部署必须充分理解能力边界与风险:规划、工具选择、反思机制决定效果;安全措施决定能否在真实环境中可靠、合规地运行。人机协作将是释放智能体潜力的关键路径。