目前,开发者利用大模型和 AI 辅助编程工具来加速编码过程的选择越来越多。随着大模型技术的快速发展,模型的更新和发布速度也在不断加快,例如今年发布的 Claude Sonnet 3.7 和 GPT-4.1。这些新模型的可访问性正变得越来越高,使开发者能够更更加轻松地使用它们。然而,这也带来了新的挑战:开发者需要判断在不同的工作场景中,应该选择哪个模型来最有效地完成任务。
推理模型最佳实践
根据 OpenAI 提供的官方建议来看,使用推理模型的最佳实践包括:
- 保持简单直接:推理模型擅长理解和回应简短、明确的指令。
- 避免提示思维链:这些模型内部已经进行推理,无需提示它们“逐步思考”或“解释你的推理”。
- 使用分隔符以提高清晰度:利用分隔符如 markdown、XML 标签和部分标题,明确区分输入的不同部分,帮助模型准确解释。
- 首先尝试零样本,再尝试少样本:推理模型通常不需要少样本示例就能产生良好的结果,因此先编写不带示例的提示。如果输出要求复杂,可以包含一些输入和期望输出的示例。确保这些示例与提示指令高度一致,否则可能导致结果不佳。
- 提出具体要求:如果希望模型在响应中遵循特定限制(例如“提出一个预算低于 500 美元的解决方案”),请在提示中明确说明这些限制。
- 给出尽可能具体的目标:在提示中提供非常具体的参数,并鼓励模型不断推理和迭代,直到符合您的成功标准。
多模态模型
多模态大模型通过整合不同类型的数据,能够更全面地理解和响应用户需求,同时处理文本、图像和视频数据,从而提供更智能的搜索和推荐服务。例如,开发者可以借助多模态模型来直接生成 SVG/PNG 图形,或者直接基于视频图像进行提问。主流的多模态模型包括 GPT-4o(文本、图像、音频), Gemini 2.5(文本、图像、音频、视频) 等。
图:谷歌的 Gemini 模型提供了直接基于视频上下文进行提问的能力
选择模型时需要考虑哪些因素
任务复杂度
对于简单任务,例如明确的编码需求,包括生成工具函数、执行语法转换、或创建数据处理脚本,通常只需要选择具备核心代码知识的快速模型即可。这类模型如 GPT-4o 和 Claude-3.7-Sonnet 能够更快地处理代码,无需复杂的推理过程即可快速完成任务。
对于复杂任务,例如对给定代码进行 CodeReview 或代码风险识别、处理设计意图不明确的交互、构建复杂的多阶段数据分析脚本,则需要选择推理模型。这些模型可以帮助我们快速拆解问题的复杂度,并基于此构建解决方案。常用的编程类推理模型包括 Claude-3.7-Sonnet-Thinking、o4-mini 等。
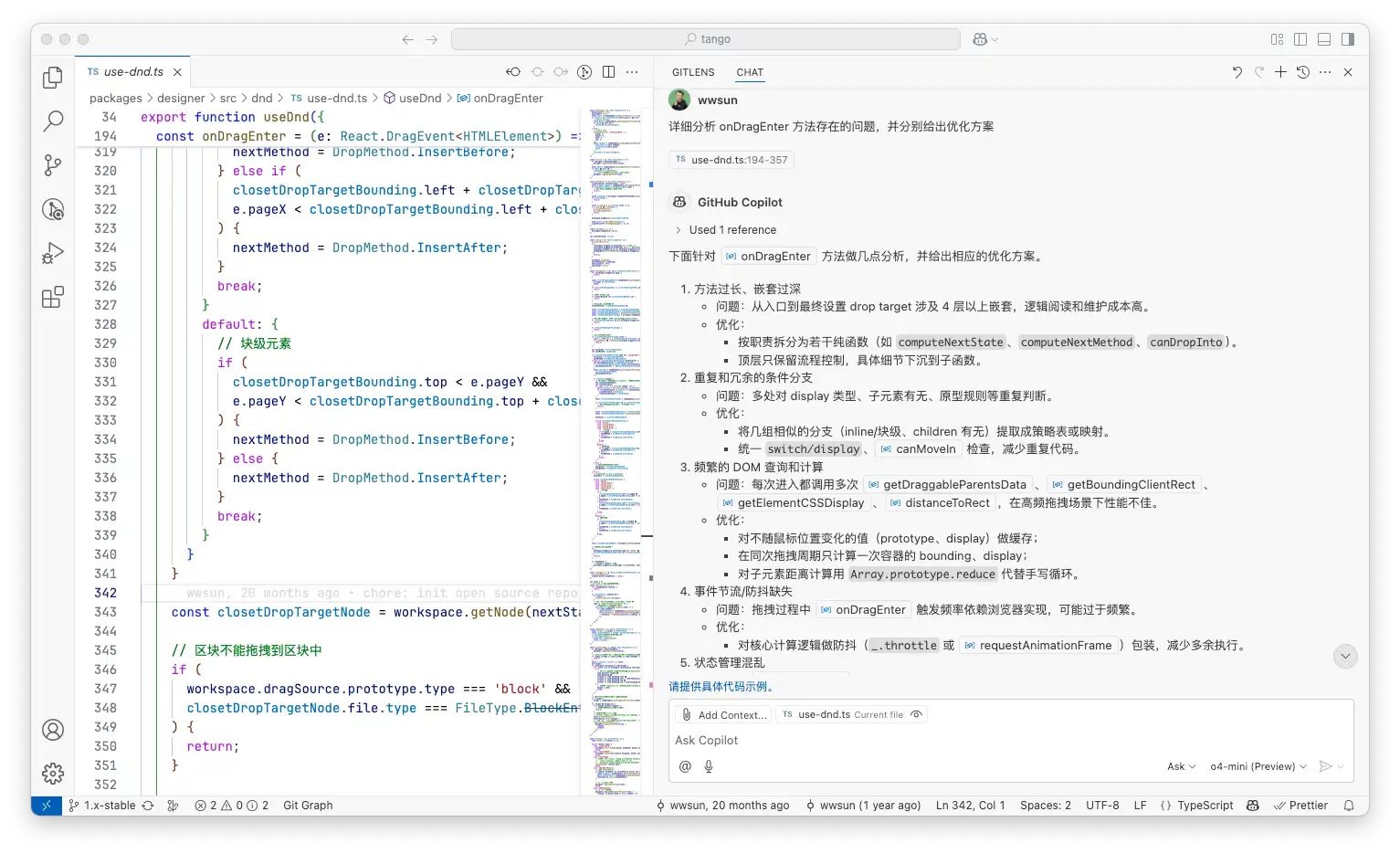
图:使用推理模型 o4-mini 进行 CodeReview,示例内容为开源代码
延迟和输出速度
模型的延迟(从提问回复的第一个 Token 返回)和输出速度是我们在日常编码工作中使用 AI 辅助的关键因素,因为它决定了我们能否顺畅地在编写代码时获得 AI 的辅助提示并进行快速的代码补全。延迟过高的模型会导致开发过程频繁中断。
对于日常的快速编码任务,例如行内代码补全、工具函数生成等,我们可以选择快速响应类模型。这类模型大多属于非推理类,包括 Gemini-2.0-Flash、GPT-4.1、GPT-4o 等,它们能快速且顺畅地辅助完成快速的完成响应,可以作为日常任务的首选。
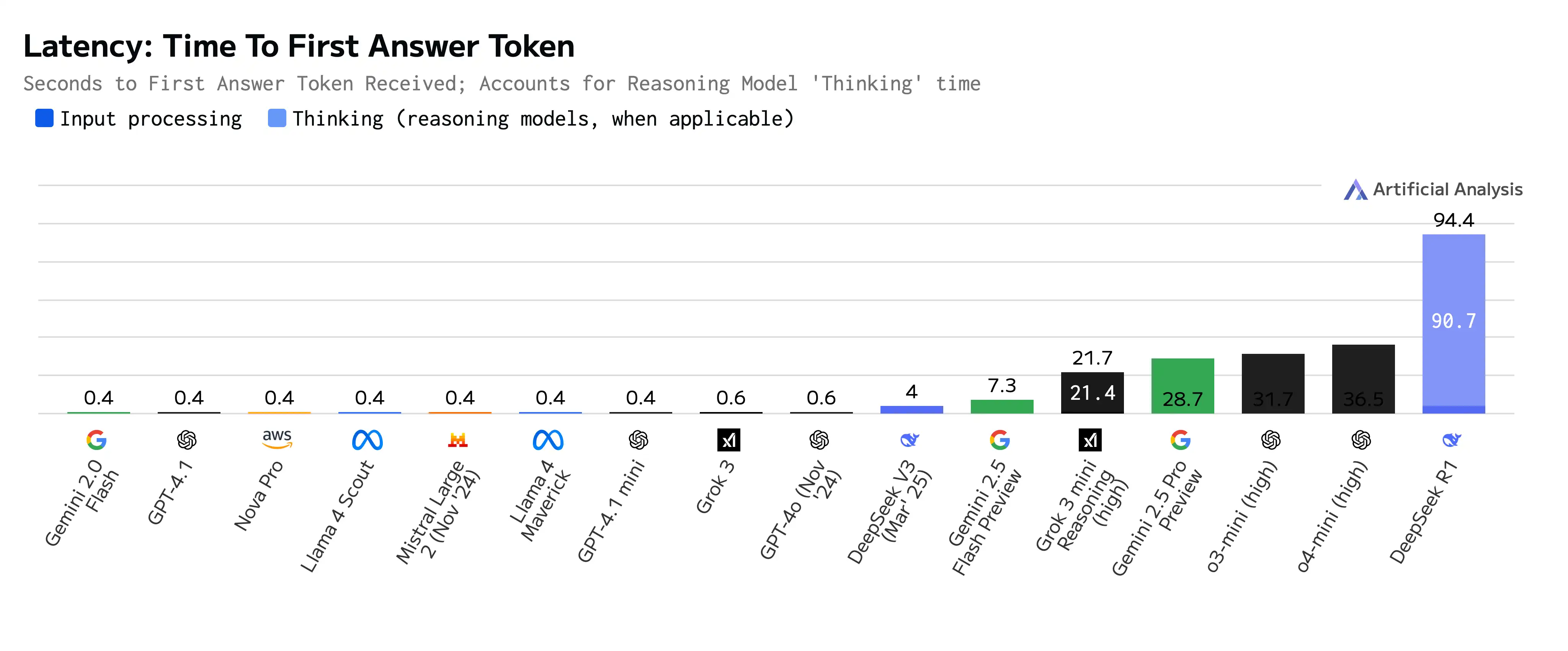
图:模型延迟对比
相比之下,如果你需要从零创建一个项目、组件、功能复杂的函数,或者分析大块代码中的问题,延迟可能不是首要考虑因素。在这种情况下,关注任务完成效果更为重要。通过使用推理模型,尽管会有一定的请求延迟,但可以获得质量更高的结果。
上下文窗口尺寸
上下文窗口尺寸指的是模型能处理的最大输入数据量,通常以 token 数表示。每个模型都有其输入输出 token 的限制,推理过程也会消耗上下文窗口。较大的上下文窗口意味着模型能接收更多信息,从而提供更精准的结果。
在处理大型代码库或解决来自旧代码库的问题时,较大的上下文窗口会非常有帮助,它将有助于生成更完整的结果。例如,Gemini 2.5-Pro 支持 1000k tokens 上下文窗口(可以铺满约 1500 张 A4 纸,使用 12 号 Arial 字体),而 GPT-4o 仅支持 128k 的上下文窗口。因此,对于重构大型代码库、修改复杂项目代码,或者基于旧代码库生成文档或测试用例,Gemini 2.5-Pro 会是更好的选择。
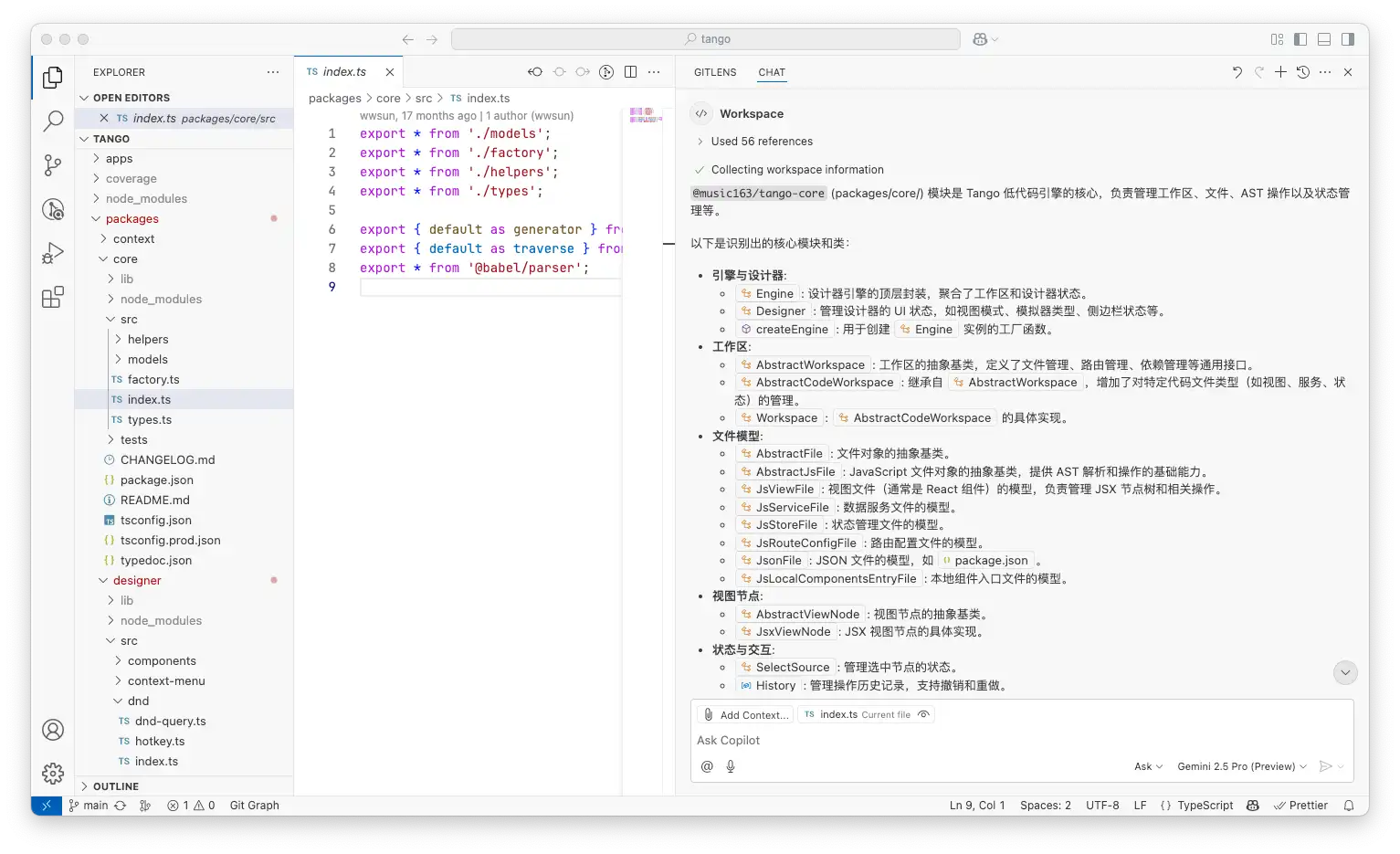
图:使用 Gemini 2.5-Pro 来阅读大型代码库的代码,并生成类图,示例内容为开源代码
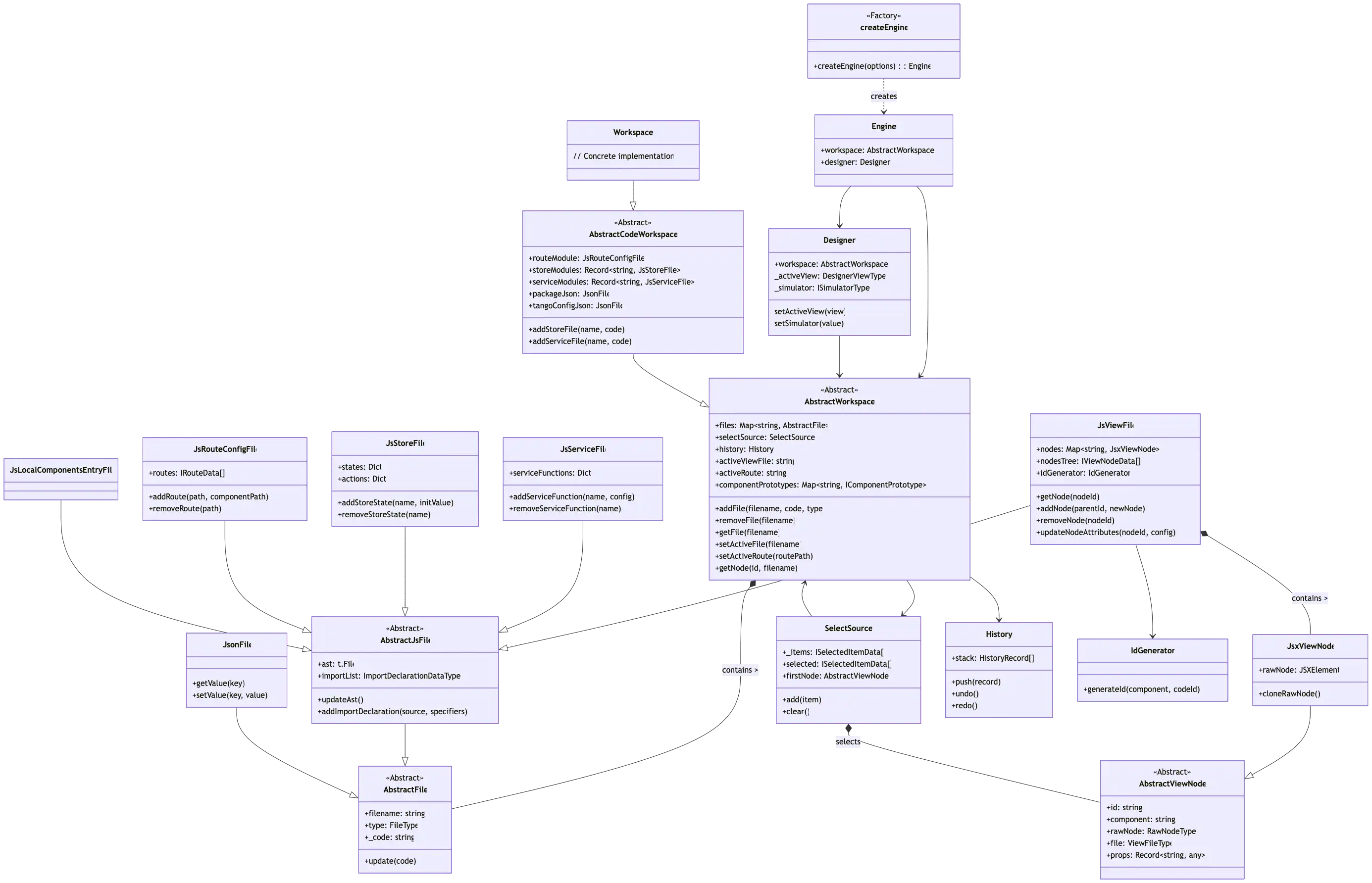
图:使用 Gemini 2.5-Pro 生成的NetEase/Tango项目的类图
当然,如果你的任务不需要大量上下文,比如编写单个函数或生成独立的单元测试,选择具有较小上下文窗口但推理能力强的模型可能会更高效。对于大多数典型的编码任务,如果不需要一次性分析整个项目,较小的上下文窗口通常就足够了,并且还能增强模型对当前任务的专注度。
知识的及时性
知识的及时性也是一个重要的考虑因素,尤其是在使用新的库或框架时。较早发布的模型可能难以准确处理更新频繁的信息。例如,当你希望借助模型来升级或迁移某个框架(如将 webpack 迁移到 rspack,或升级 nodejs 版本)时,使用发布更晚的模型会更有优势。例如,2024 年 12 月 11 日发布的 Gemini 2.0 Flash 或 2025 年 2 月 24 日发布的 Claude 3.7 Sonnet 都是不错的选择。
对于不依赖最新编程知识的任务,我们不必纠结于使用最新的模型。对于大多数场景,响应速度和模型的价格仍然是优先考虑的因素。通常,我们可以借助一些模型对比工具来获取模型的最新参数信息。
模型对比工具 https://artificialanalysis.ai/leaderboards/models
模型能力一览
我们可以从模型对比工具中快速了解到,在任务处理能力、输出速度、延迟、价格、上下文尺寸方面当前模型的能力。这将有助于你快速的做出决策。
主流模型的能力和使用场景推荐
最后,对于日常开发工作中,这里给出一个快捷的模型选择指南。你也可以参考 Github Copilot 的模型选择指南。
简单任务:低延迟,低成本
首选:GPT-4.1 备选: Claude-3.7-Sonnet
GPT-4.1 是 OpenAI 的 GPT-4o 模型的改进版本。 此模型是常见开发任务(受益于速度、响应能力和常规用途推理)的强大默认选项。 在处理需要广泛知识、快速迭代或基础代码理解的任务时,GPT-4.1 相比 GPT-4o 有显著改进。
常见场景:
轻量级任务,不需要太大的上下文尺寸
日常编码任务
创建和编辑文档
简单的代码重构
复杂任务:深度推理,问题识别,性能优化,复杂编码
首选:Claude-3.7-Sonnet-Thinking 备选:o1, o4-mini
Claude 3.7 Sonnet 在软件开发生命周期的各个阶段(从初始设计、错误修复、维护到性能优化)均表现出色。 它特别适合用于多文件重构或架构规划等需要理解跨组件上下文的场景。
常见场景:
实施 code review
生成单元测试方案
代码迁移
不明确的交互 UI 生成
规划实施方案
绘制技术架构图
大型的复杂代码库:长上下文理解,复杂指令执行和固化
首选:Gemini 2.5 Pro 备选:Gemini 2.0 Flash
Gemini 2.5 Pro 非常适合高级编码任务,例如开发复杂算法或调试复杂的代码库。 它能够通过分析数据并生成跨多领域的见解来辅助科学研究。 它的长上下文处理能力使它能够有效管理和理解大量文档或数据集。 Gemini 2.5 Pro 是需要强大模型的开发人员的理想选择。
常见场景:
理解老旧代码库
参与大型代码库开发
基于完整代码库生成文档
多模态:图生码、图像分析
首选:Gemini 2.5 Flash 备选:GPT-4o
Gemini 2.5 Flash 支持图像输入,开发人员可以在执行 UI 检查、图表分析或布局调试等任务时引入视觉对象上下文。 这使得 Gemini 2.5 Flash 特别适用于需要图像增强问题解决的场景,例如请求 Copilot 分析 UI 截图中的辅助功能问题,或帮助理解布局中的视觉对象 Bug。
生成架构图(svg)
基于给定的图形生成代码
例如,我们可以直接使用 Geimini 从一张给定的截图生成代码
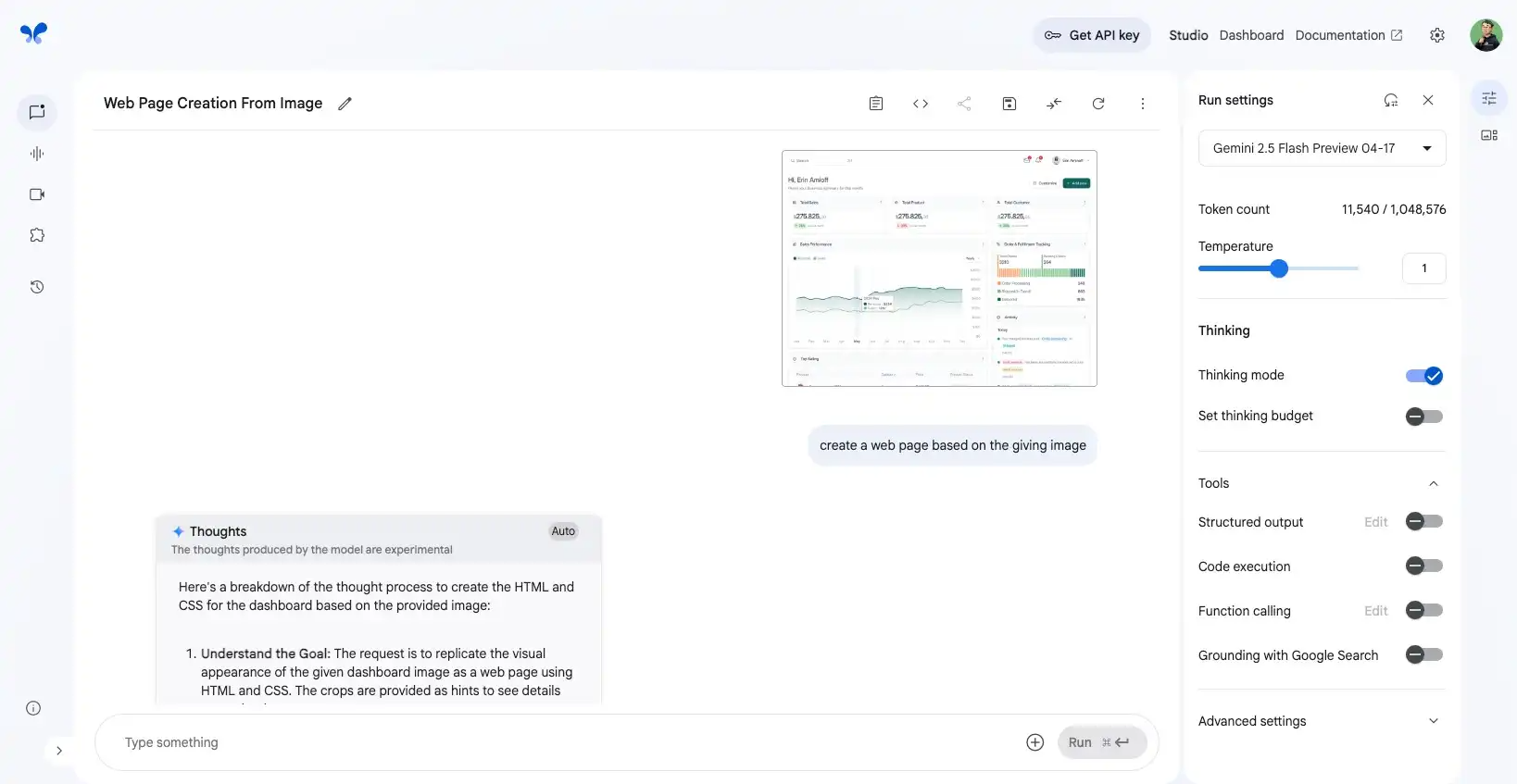
生成的代码效果如下,代码未经任何调整,还原度非常的高
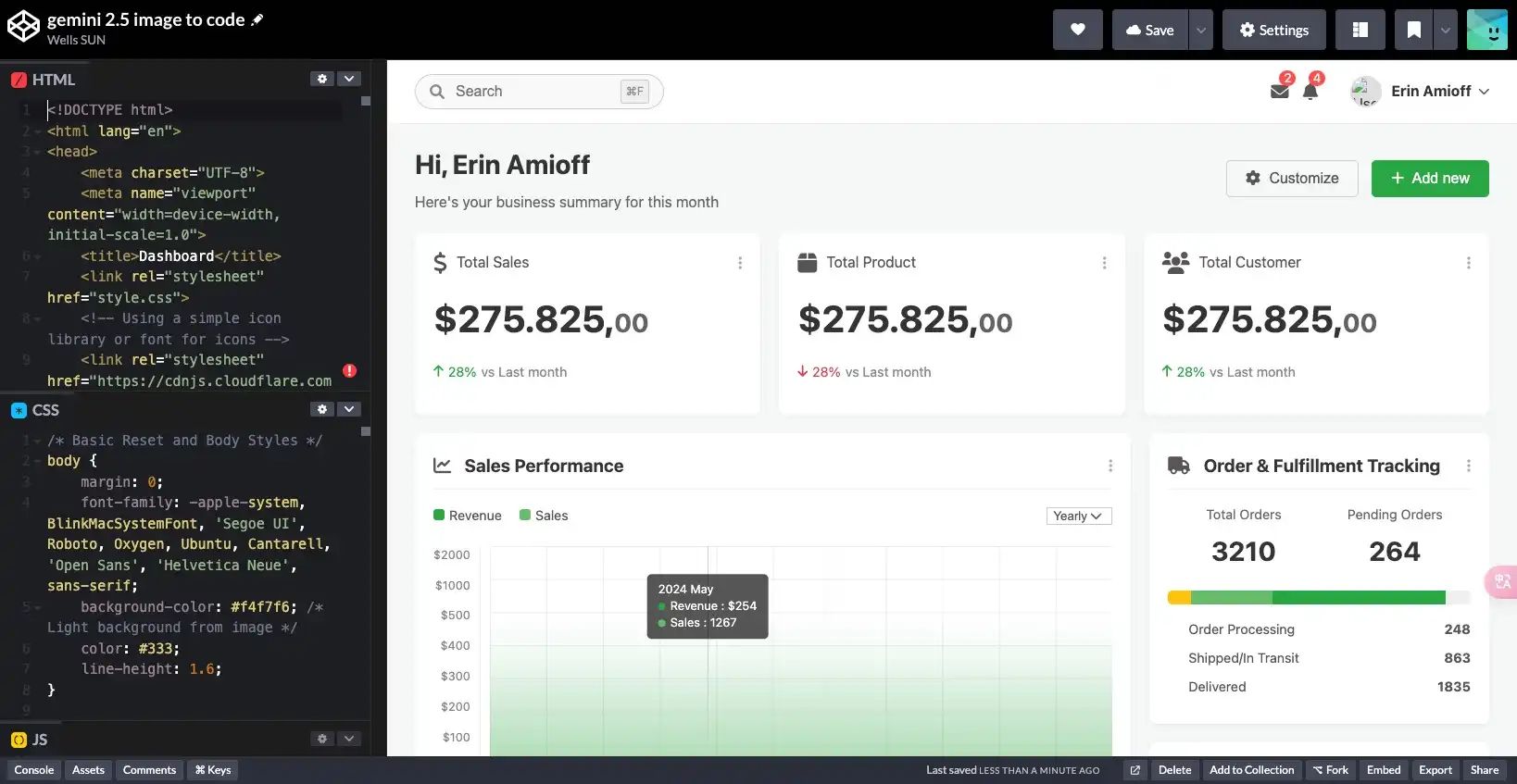
总结
在日常的开发工作中,如何选择合适的 AI 编程模型来提升效率,一直是我关注的重点。在这篇文章中,我分享了关于推理模型和多模态模型的一些使用心得和最佳实践。同时,我也总结了在挑选模型时,我们通常需要考量的几个关键维度:任务的复杂度、模型响应速度、上下文窗口的限制,以及模型知识库的新旧程度。
针对不同的开发场景,比如处理简单快捷的编码任务、应对复杂的逻辑挑战、驾驭庞大的代码库,或是探索图生代码等多模态应用,我都给出了一些主流模型的选择建议。希望这些经验能帮助大家在面对众多 AI 辅助编程工具时,能够更清晰地判断和选择,从而让 AI 真正成为我们编码路上的得力助手。